Machine Learning for Missing well Logs data Regression
Random Forest Regression for Petrophysics Analysis
Introduction
Dalam eksplorasi dan produksi minyak dan gas, salah satu tantangan utama yang sering dihadapi adalah data logging yang hilang pada interval tertentu, yang dapat memengaruhi analisis dan interpretasi reservoir. Salah satu solusi yang dapat digunakan untuk mengatasi masalah ini adalah dengan memanfaatkan machine learning (ML), khususnya algoritma regresi seperti Random Forest. Pada studi ini, regresi menggunakan log gamma ray (GR) sebagai fitur utama telah berhasil memprediksi log sonic time (DT) yang hilang, dengan hasil yang menjanjikan.
Method
Dalam eksperimen ini, saya mengembangkan model regresi menggunakan Random Forest untuk memprediksi nilai DT berdasarkan korelasi yang ada dengan Gamma Ray (GR) log. GR adalah log yang umumnya lengkap pada interval sumur yang sulit atau tidak dapat diukur, dan oleh karena itu dapat menjadi fitur yang sangat berguna untuk memprediksi nilai DT pada bagian data yang hilang.
Data
Data yang digunakan adalah data logging sumur dari Volve field, Norwegia, yang diunduh secara open source. Lapangan ini dikembangkan oleh Equinor (https://www.equinor.com/energy/volve-data-sharing). Ada banyak sumber open source lain yang dapat digunakan sebagai sumber, beberapa yang mudah diakses antara lain : Western Australia NOPIMS: https://www.ga.gov.au/nopims NLOG Dutch Oil and Gas Portal: https://www.nlog.nl/en/welcome-nlog Pada studi ini, analisis dilakukan sepenuhnya di google colab
1
2
3
4
from google.colab import files
uploadlas = files.upload()
df = pd.read_csv('volve_wells.csv', usecols=['WELL', 'DEPTH', 'RHOB', 'GR', 'NPHI', 'PEF', 'DT'])
df['WELL'].unique()
Dipilih beberapa well untuk training dan testing data dan dilakukan splitting
1
2
3
4
5
6
7
# Training Wells
training_wells = ['15/9-F-11 B', '15/9-F-11 A', '15/9-F-1 A']
# Test Well
test_well = ['15/9-F-1 B']
train_val_df = df[df['WELL'].isin(training_wells)].copy()
test_df = df[df['WELL'].isin(test_well)].copy()
train_val_df.describe()
Random Forest Regression dan Prediksi DT dengan Gamma Ray
Data perlu melalui proses filtering untuk menghilangkan nilai NaN untuk semua parameter. Selanjutnya Random Forest Regressor untuk memodelkan hubungan antara Gamma Ray (GR) dan Sonic Log (DT). Semakin banyak data tentunya akan semakin baik, namun pada kasus kali ini, beberapa data log neutron dan resistivity juga missing. Untuk mengurangi pengaruh bias dan error, hubungan GR dan DT digunakan.
Setelah model dilatih, saya menggunakannya untuk memprediksi nilai DT berdasarkan nilai GR sepanjang kedalaman sumur pengujian. Model ini memungkinkan untuk memprediksi nilai DT yang hilang pada kedalaman tertentu yang tidak memiliki data.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor
df_train = test_df.dropna(subset=['DT', 'GR'])
X_train = df_train[['GR']]
y_train = df_train['DT']
model = RandomForestRegressor()
model.fit(X_train, y_train)
#prediksi DT pada semua kedalaman
X_all = test_df[['GR']] # only GR is used as predictor
test_df['DT_predicted_from_GR'] = model.predict(X_all)
Smoothing
Untuk mengurangi fluktuasi atau kekasaran dalam prediksi DT, kami menggunakan metode rolling average untuk menghaluskan nilai yang telah diprediksi. Rolling window yang digunakan adalah 15 titik untuk menciptakan prediksi yang lebih halus dan lebih representatif.
1
2
# dilakukan smoothing menggunakan rolling average
test_df['DT_predicted_smoothed'] = test_df['DT_predicted_from_GR'].rolling(window=15, center=True, min_periods=1).mean()
Visualisasi
Untuk memahami seberapa baik model bekerja, kami memvisualisasikan hasil prediksi (baik yang mentah maupun yang telah dihaluskan) dan membandingkannya dengan DT aktual. Berikut adalah grafik yang menunjukkan perbandingan antara DT Aktual dan DT Prediksi yang Di Haluskan sepanjang kedalaman.
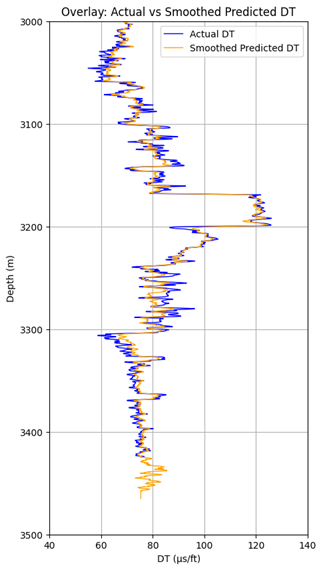
{: .center }Actual vs Predicted Sonic log (3100-3500 m)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
# Visualisasi
plt.figure(figsize=(5, 10)) # Format seperti tampilan log
plt.plot(test_df['DT'], test_df['DEPTH'], label='Actual DT', color='blue', linewidth=1)
plt.plot(test_df['DT_predicted_smoothed'], test_df['DEPTH'], label='Smoothed Predicted DT', color='orange', linewidth=1)
plt.gca().invert_yaxis() # Kedalaman makin besar ke bawah
plt.xlabel('DT (μs/ft)')
plt.ylabel('Depth (m)')
plt.xlim(40, 140) # Rentang DT
plt.ylim(3500, 3000) # Zoom ke kedalaman 3000–3500m
plt.legend()
plt.grid()
plt.title('Overlay: Actual vs Smoothed Predicted DT')
plt.show()
# Missing data values regression
plt.figure(figsize=(12, 8))
# Plot 1: Gamma Ray
plt.subplot(1, 3, 1)
plt.plot(test_df['GR'], test_df['DEPTH'], color='green')
plt.gca().invert_yaxis()
plt.xlabel('GR (API)')
plt.title('Gamma Ray')
plt.ylim(3500, 100)
plt.grid(True)
# Plot 2: Actual DT (where available)
plt.subplot(1, 3, 2)
plt.plot(test_df['DT'], test_df['DEPTH'], label='Actual DT', color='blue')
plt.gca().invert_yaxis()
plt.xlabel('DT (us/ft)')
plt.title('Actual DT')
plt.ylim(3500, 100)
plt.grid(True)
# Plot 3: Smoothed Predicted DT
plt.subplot(1, 3, 3)
plt.plot(test_df['DT_predicted_smoothed'], test_df['DEPTH'], label='Smoothed Predicted DT', color='orange')
plt.gca().invert_yaxis()
plt.xlabel('DT (us/ft)')
plt.title('Smoothed DT (from GR)')
plt.ylim(3500, 100)
plt.grid(True)
plt.tight_layout()
plt.show()
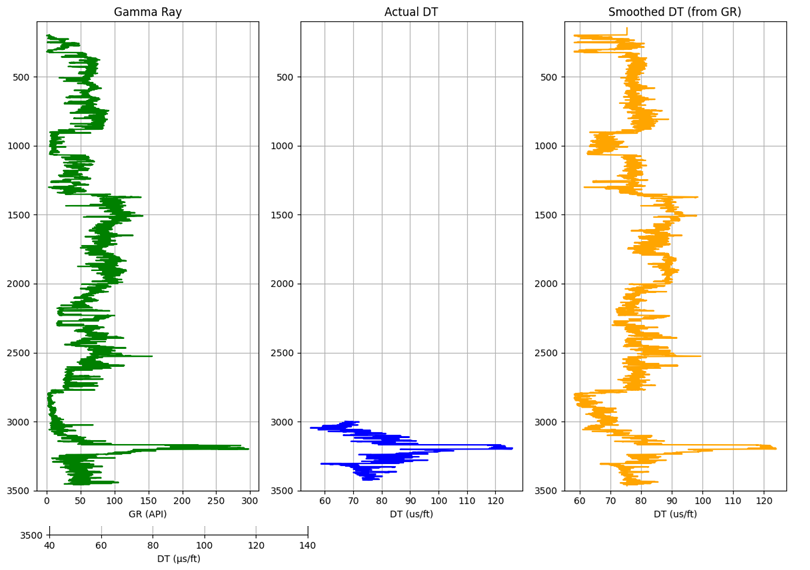
{: .center }Left (GR log), Mid (Actual DT log with missing values), right(Predicted DT)
Evaluasi Model
Setelah melakukan prediksi dan penghalusan, kami mengevaluasi model dengan menghitung beberapa metrik akurasi, seperti Mean Absolute Error (MAE), Mean Squared Error (MSE), Root Mean Squared Error (RMSE), dan R-Squared (R²). Metrik-metrik ini memberikan gambaran tentang seberapa dekat prediksi model dengan nilai DT yang sebenarnya.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
#Assesment dan Evaluasi
test_df['smoothed_TEST_DT'] = test_df['DT_predicted_from_GR'].rolling(window=15, center=True, min_periods=1).mean()
valid_rows = test_df[['DT', 'smoothed_TEST_DT']].dropna()
residuals_smoothed = valid_rows['DT'] - valid_rows['smoothed_TEST_DT']
# Accuracy metrics
mae_smoothed = mean_absolute_error(valid_rows['DT'], valid_rows['smoothed_TEST_DT'])
mse_smoothed = mean_squared_error(valid_rows['DT'], valid_rows['smoothed_TEST_DT'])
rmse_smoothed = np.sqrt(mse_smoothed)
r2_smoothed = r2_score(valid_rows['DT'], valid_rows['smoothed_TEST_DT'])
# Print results
print(f"Mean Absolute Error (MAE): {mae_smoothed:.4f}")
print(f"Mean Squared Error (MSE): {mse_smoothed:.4f}")
print(f"Root Mean Squared Error (RMSE): {rmse_smoothed:.4f}")
print(f"R-Squared (R²): {r2_smoothed:.4f}")
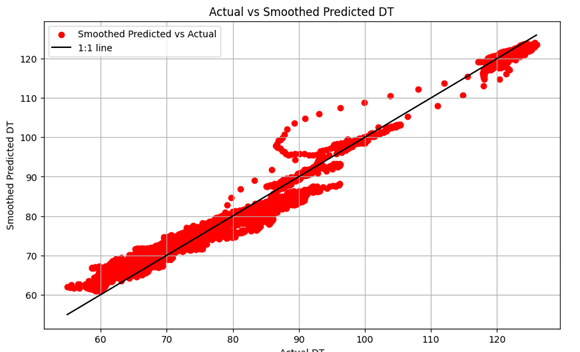
Saya juga melakukan plot residuals (selisih antara nilai aktual dan nilai prediksi) untuk memeriksa apakah model bekerja dengan baik di seluruh kedalaman. Selain itu, scatter plot antara nilai DT Aktual dan DT Prediksi yang Di Haluskan digunakan untuk melihat sejauh mana keduanya berhubungan.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# Residual plot
plt.figure(figsize=(10, 6))
plt.scatter(valid_rows.index, residuals_smoothed, color='blue', label='Residuals')
plt.axhline(0, color='black', linestyle='--', linewidth=2)
plt.xlabel('Index / Depth')
plt.ylabel('Residuals (Actual - Smoothed Predicted)')
plt.title('Residual Plot (Smoothed)')
plt.grid(True)
plt.legend()
plt.show()
# Actual vs Smoothed Predicted Plot
plt.figure(figsize=(10, 6))
plt.scatter(valid_rows['DT'], valid_rows['smoothed_TEST_DT'], color='red', label='Smoothed Predicted vs Actual')
plt.plot([valid_rows['DT'].min(), valid_rows['DT'].max()], [valid_rows['DT'].min(), valid_rows['DT'].max()], 'black', label="1:1 line")
plt.xlabel('Actual DT')
plt.ylabel('Smoothed Predicted DT')
plt.title('Actual vs Smoothed Predicted DT')
plt.legend()
plt.grid(True)
plt.show()
Assessment
Berikut adalah hasil dari evaluasi model yang menggunakan data log yang lengkap untuk pelatihan dan prediksi terhadap data yang hilang:
Mean Absolute Error (MAE): 2.0122
Mean Squared Error (MSE): 6.9704
Root Mean Squared Error (RMSE): 2.6402
R-Squared (R²): 0.9677
Hasil evaluasi ini menunjukkan bahwa model memiliki akurasi yang sangat baik, dengan R² yang mencapai 0.9677, yang menunjukkan bahwa model dapat menjelaskan sekitar 96.77% dari variabilitas data aktual. Kesalahan prediksi yang rendah (MAE, MSE, dan RMSE yang relatif kecil) juga menunjukkan bahwa model mampu memberikan hasil yang dapat diandalkan. Dengan demikian, model ini dapat digunakan untuk mengisi nilai DT yang hilang dan memberikan prediksi yang sangat akurat sepanjang kedalaman sumur, yang penting untuk aplikasi lebih lanjut seperti estimasi porositas efektif, saturasi air, dan interpretasi facies yang lebih komprehensif.
Model ini juga dapat diterapkan dalam pemodelan statik reservoir, memungkinkan perhitungan lebih akurat meskipun data log DT tidak lengkap, yang dapat membantu dalam pengambilan keputusan yang lebih baik di lapangan.